Data Preprocessing In Python.
Hello, guys did you hear, see the above terminology data preprocessing? Those who want to be Data Scientist or Data wranglers must be aware of this terminology.
This is the most important part of Machine Learning, Artificial Intelligence, Data Science, Computer Vision, Deep learning, etc…
Data preprocessing :
This is the first step towards any Machine learning algorithms or any algorithms. Because algorithms accept some properly formatted data we need to provide data in the same format as it required.
For example,
Suppose we are filling online scholarship form and there are various fields among that is upload a photo(size < 2 Mb). Here we have a photo but not with size less than 2 Mb at that time what are your options? Simply we go online find one file compressor and compress the photo and then upload. This process of converting more Mb file into less than 2 Mb file is simply called Data Preprocessing.

Data preprocessing is a process of data cleaning, data formatting for a proper format so that we can use that to any algorithms. Data preprocessing is the part where most of the data scientists spend most of their time. Also, data preprocessing is one of the challenging and most loved parts of data scientists.
So how to begin data preprocessing?
The following are important steps in data preprocessing.
Data preprocessing steps:
#1. Import libraries
#2. Import dataset
#3. Matrix of features
#4. Missing data management
#5. Categorical data management
#6. Splitting of dataset
#7. Feature scaling
For this, we are using a Spyder tool.
Import libraries:
We often use the preloaded packages, libraries, class, etc to ease our calculation or process. So what is the difference between packages, libraries?
The package is a set of libraries. libraries contain important class functions.


Here in import numpy, numpy is the library and sklearn is a package and SimpleImputer is a library.
The following three are most important libraries data preprocessing.

Import dataset:
The dataset is our input for the algorithms. We use the panda library to import data.

Matrix of features:
If we are taking data input in the .csv format so every cell of that file is called a feature. Generally, a matrix of feature means giving meaning to a dataset. There are two types of features present as follows.
a. Independent features: The cells or features which are independent.
b. Dependent features: The cells or features which depend on independent features.


Here, X is an independent feature and Y is a dependent feature and we have to be careful about the indexing, try to understand syntax of indexing. Apply different indexing and see what it holds.
Missing data management:
So when we say we want 100% accuracy there are various factors we need to understand first, is our dataset is true dataset(100% valid) and is it complete? Missing values from small or large datasets can cause a problem in accuracy and prediction.
We use the SimpleImputer library to do that task.

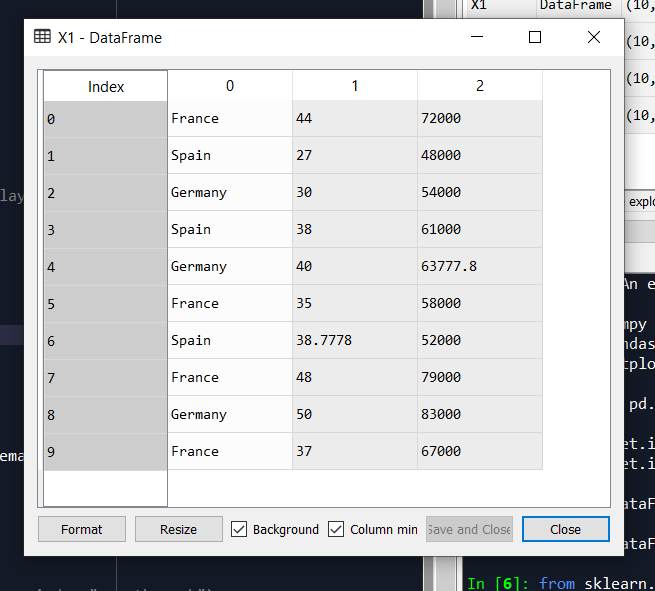
Here we use strategies like mean, median, and mode. The missing value from dataset is represented as nan.
Categorical data management:
The following is types of data present.
- Numerical data: Represents quantitative measurements. Numerical data contains Discrete data (Proper countable) and Continuous data (Infinite possible values)
- Categorical data: The data that has no mathematical meaning. For example True, False etc.
- Ordinal data: It is a mixture of numerical and categorical data. For example 1–5 scale where 5 is perfect and 1 is worse.
So is very important that we need to assign some mathematical value to the categorical data. Like True = 1 and False = 0.
We use ColumnTransformer, OneHotEncoder, and LabelEncoder libraries for this job from the sklearn package.
LabelEncoder: It is used to give labels to the categorical data like True = 1 and False = 0.
OneHotEncoder: Once we complete the LabelEncoding then we may face this issue like 1 is greater than 0 so it is dominant? So we need to remove that nature because as per mathematics 1>0. At this very point, we use OneHotEncoder which will solve the problem.

Here [0] index of the column that contains categorical data. It is not that necessary to use LabelEncoder and OneHotEncode every time some time only Labeling is required.
Splitting of dataset:
We are splitting our dataset into two parts: a Training set and Testing set. The standard ratio is 70:30 but it depends on your choice. On the training set, we are going to train our algorithm and on test dataset, we are going to perform testing and find out the performance of our modules.

We use the train_test_split library from the sklearn package. As we see we pass our matrix of features and then give test size.
Feature Scaling:
Why do we need scaling?
Feature scaling is one of the most important of Data preprocessing. We may face performance or accuracy issues due to not scaled data.
For example, We have X = 1 and Y = 100000 let say we need to perform some operations on then Y-X = 99999 so we see the result shows me that Y is dominant and X has very poor participation in results. But in reality, it is not true both X and Y are equally important so how to remove that dominant nature of Y? We have an answer with us that is -> Feature scaling.
Feature scaling means scale all data in same format so that is remove the dominant nature of any features.
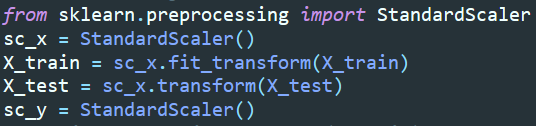
We use the StandardScaler library from the sklearn package.
Practical Scene:

# 1. Import pre-libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 2. Import dataset
dataset = pd.read_csv(‘Data.csv’)
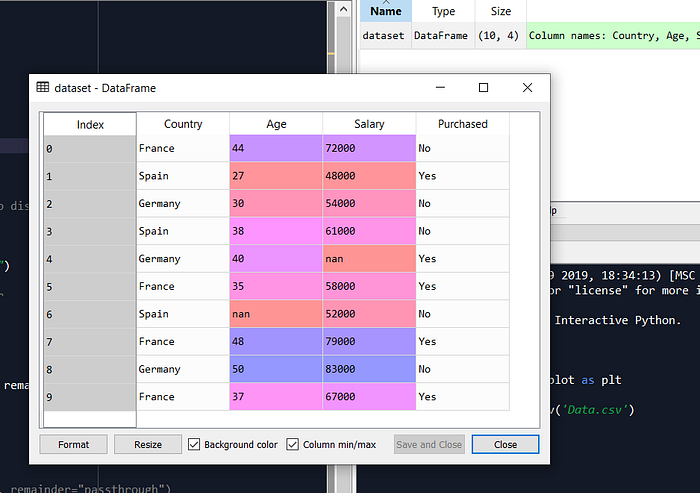
# 3. Matrix of features
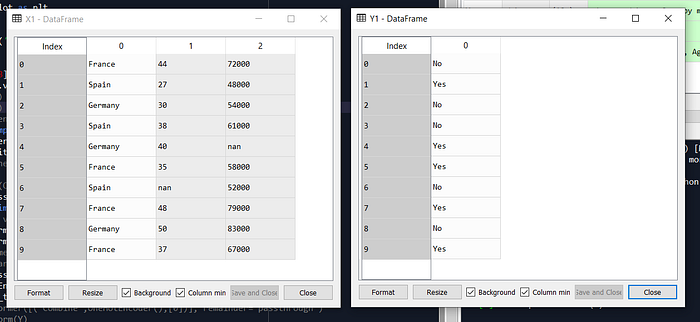
X = dataset.iloc[:,0:3].values
Y = dataset.iloc[:,3].values
# 4. Missing data management
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan,strategy=”mean”)
X[:, 1:3] = imputer.fit_transform(X[:, 1:3])
# 5. Encode and HotEncode(Categorical data)
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
# One for independent variable
clm_x = ColumnTransformer([(“Combine”,OneHotEncoder(),[0])], remainder=”passthrough”)
X = clm_x.fit_transform(X)
# One for dependent variable here we need only Label Encoder
from sklearn.preprocessing import LabelEncoder
labelencoderY = LabelEncoder()
Y = labelencoderY.fit_transform(Y)
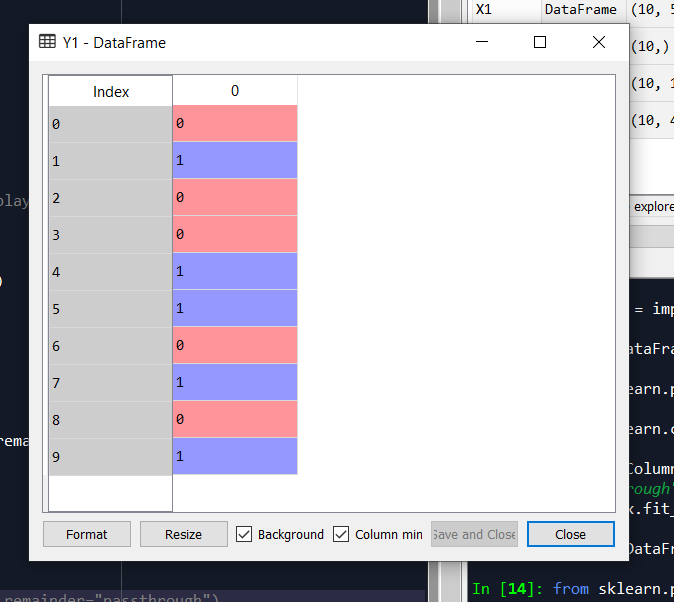
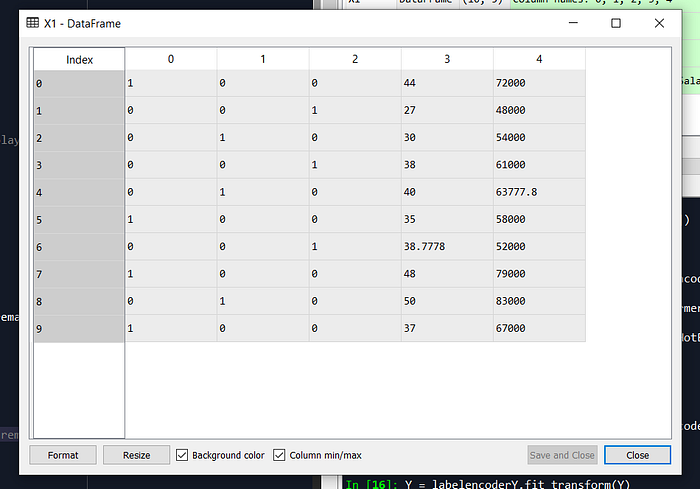
# 6. Splitting of dataset
from sklearn.model_selection import train_test_split
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.2,random_state=0)
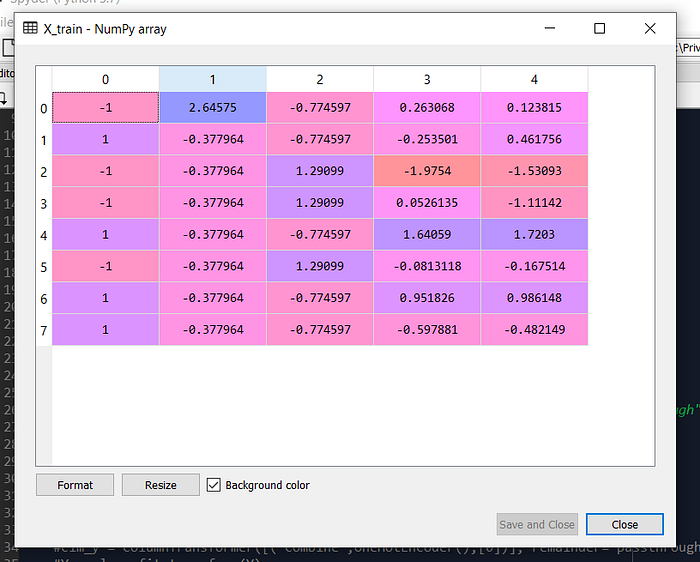
# 7. Feature scaling
from sklearn.preprocessing import StandardScaler
sc_x = StandardScaler()
X_train = sc_x.fit_transform(X_train)
X_test = sc_x.transform(X_test)
sc_y = StandardScaler()
#Y_train = sc_y.fit_transform(Y_train)
#Y_test = sc_y.transform(Y_test)
And that’s it.
Thank you all, now enjoy data preprocessing.
